嵌入(Embeddings)将项目(如单词、图像、用户、产品等)表示为数字向量。
它将高维数据转换为低维数据,同时保留关键方面,如关系或结构。
在单词方面,king(国王)和queen(女王)将有相似的数字列表(嵌入),表明它们之间的相似性。对于图像,两张狗的照片应该会产生相似的嵌入。
这些数字列表作为机器学习模型的输入,帮助做出更准确的预测。
我们来看一个关于单词的简单例子。假设我们有单词dog(狗)、cat(猫)、fish(鱼)和bicycle(自行车)。我们可以在一个非常简单的二维嵌入空间中表示这些单词,其中一个轴代表“动物性”而另一个轴代表“陆地性”。
“狗”可能被表示为[0.9,0.8],因为它是动物,并且主要是陆地生物。
“猫”可能是[0.9,0.7],因为它是动物,并且主要是陆地生物,但不如狗那么多。
“鱼”可能是[0.9,0.1],因为它是动物,但不是陆地生物。
“自行车”可能被表示为[0.1,0.8],因为它不是动物,但在陆地上使用。
嵌入通常是使用机器学习模型创建的。例如,Word2Vec、FastText和BERT是用于创建词嵌入的流行模型。
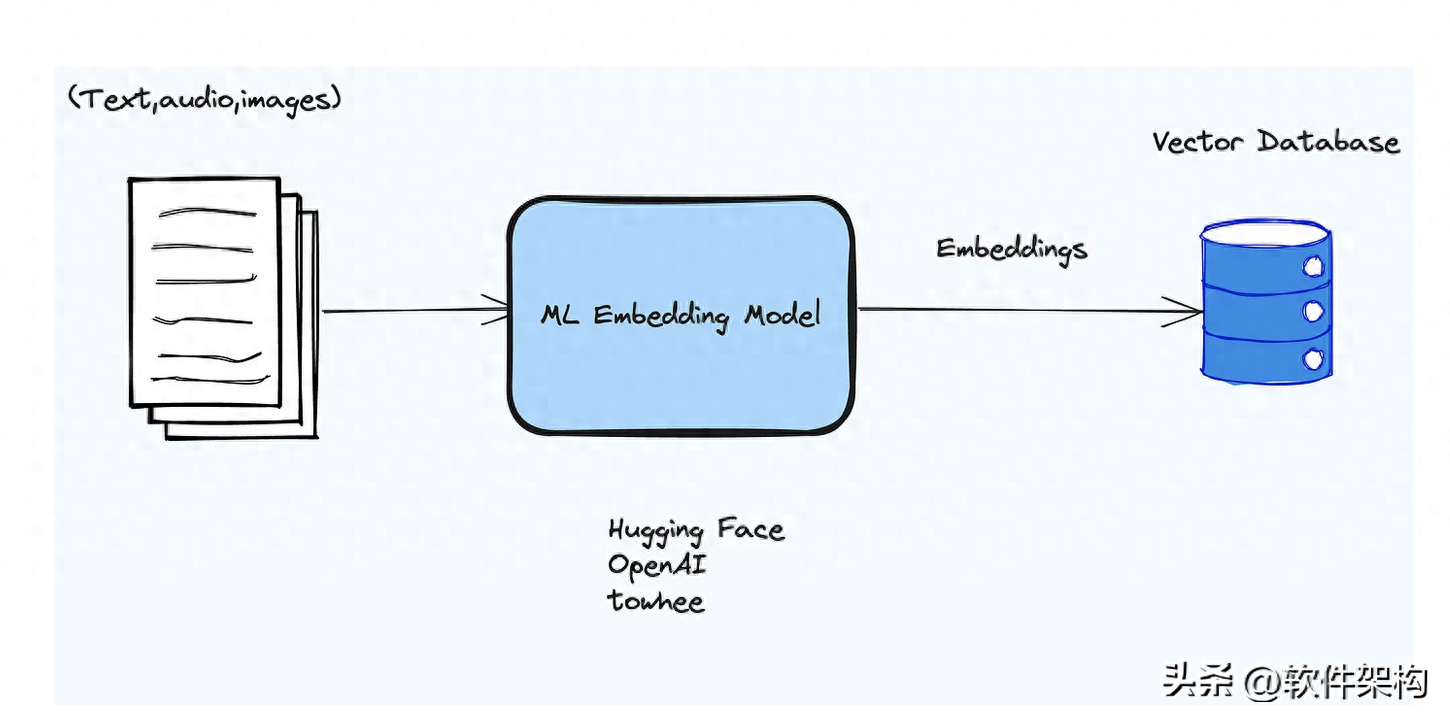
下面看看如何转换文本为嵌入向量:
导入t-SNE算法导入科学计算库numpy定义要可视化的一组单词words=['king','queen','man','woman','boy','girl','bread','butter','doctor','nurse','hospital']将向量列表转换为numpy数组,以便进行t-SNE降维n_samples=len(vectors)vectors_array=(vectors)对词向量进行t-SNE降维vectors_2d=_transform(vectors_array)在对应的位置上标注每个单词fori,wordinenumerate(words):(word,(vectors_2d[i,0],vectors_2d[i,1]))导入TensorFlow库importtensorflowastf导入CIFAR-10数据集引入numpy用于科学计算importnumpyasnp加载CIFAR-10数据集,保留前10000个训练样本(x_train,y_train),(x_test,y_test)=_data()x_train=x_train[:10000]对训练集图片进行预处理x_train_preprocessed=preprocess_input(x_train)应用t-SNE算法将高维特征向量降至二维空间tsne=TSNE(n_components=2)embeddings_2d=_transform(embeddings)显示降维后的二维嵌入图()

Towhee是一个开源的机器学习pipeline,它可以帮助我们将非结构化数据编码成嵌入。不需要编写任何代码。只需调用流水线然后进行转换即可。
示例代码,将上述图片转换为嵌入向量:
fromtowheeimportAutoPipesimportnumpyasnp对指定图片进行处理并获取输出结果output=p('./files/').get()print(output)这里假设feature是一个numpy数组,你可以根据实际情况替换为相应类型的处理方式ifisinstance(feature,):print("Shape:",)print("Data:",())else:print(feature)这段代码主要实现的功能是对指定图片使用预定义的图像嵌入管道提取特征,并详细展示提取出的所有特征向量(或特征矩阵)的信息。
输出信息:
版权声明:文章来源网络聚合,如有问题请联系删除。





